



Big Data platforma zasnovana na vodećim tehnologijama otvorenog koda
Belvedere - Big Data platforma zasnovana na tehnologijama otvorenog koda
Skalabilno rešenje zasnovano na otvorenom kodu koji optimizuje procese, ubrzava donošenje odluka i jača konkurentske prednosti. Unapredite sigurnost, prepoznajte prilike i poboljšajte performanse.

Podaci su nova valuta u savremenom poslovanju.
Međutim, mnogi od njih ostaju neiskorišćeni, nevidljivi ili nejasni. Belvedere menja ovaj scenario. Naša napredna platforma za praćenje omogućava vašoj organizaciji da uvidi skrivene uvide, poboljša sigurnost, unapredi performanse i ubrza rast.
Zasnovana na vodećim tehnologijama otvorenog koda i potpuno prilagođena potrebama vaše kompanije, Belvedere omogućava da vidite celu sliku – prošle trendove, sadašnje anomalije i buduće prilike – sve u realnom vremenu.
Kako Belvedere unapređuje vaš biznis
Belvedere omogućava ne samo upravljate da upravljate podacima, već i da njima potpuno ovladate. Evo kako to i postižemo:


Ključne funkcionalnosti


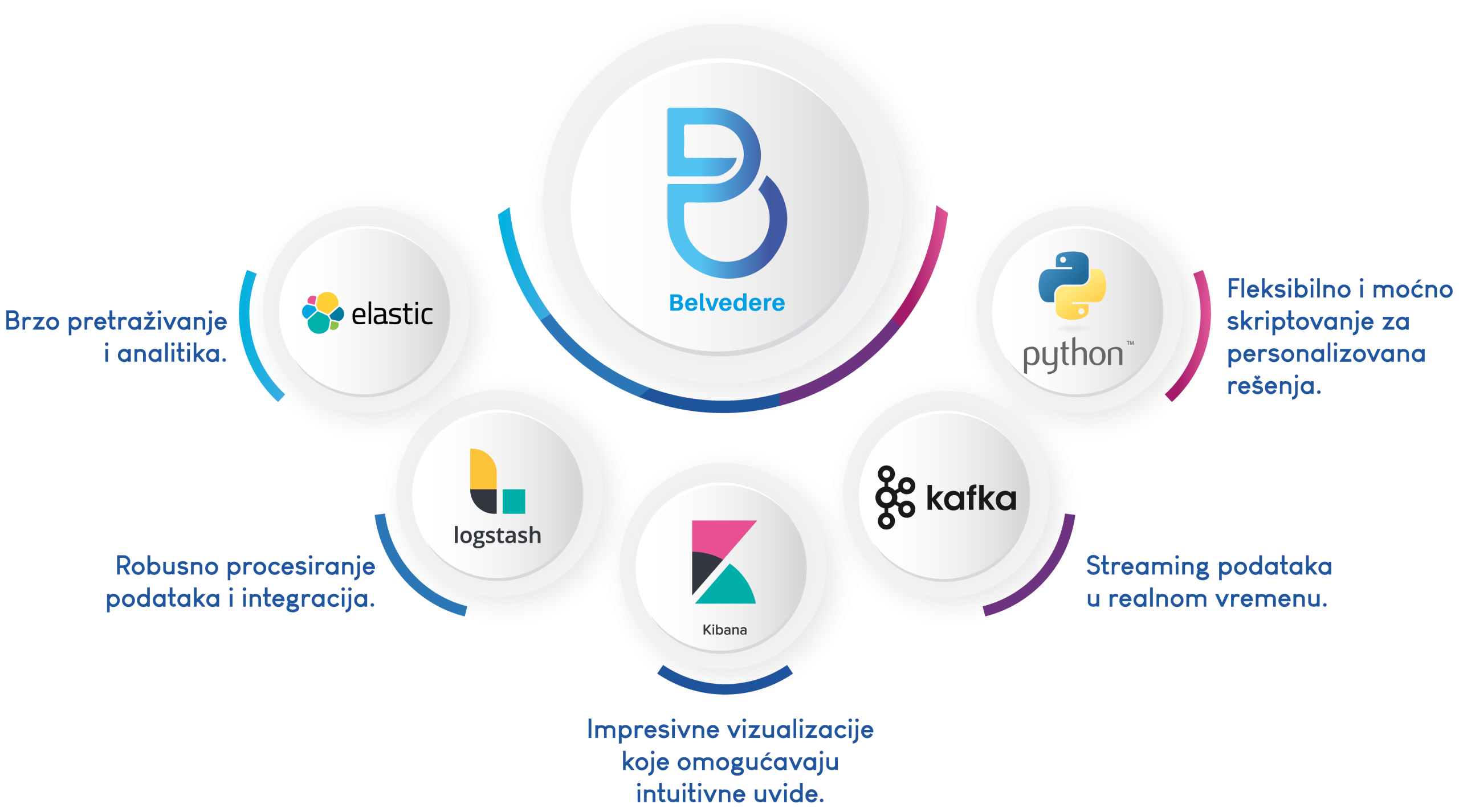
Inovacije otvorenog koda, savršeno prilagođene vama!
Belvedere koristi najbolje u inovacijama otvorenog koda, prilagođene vašim potrebama.
Zašto odabrati Belvedere?

